You probably don't need MCP
MCPs are too bloated
It’s an open secret that MCPs are too bloated. The idea is fine, but the LLMs don’t like them. I’d argue that even developers don’t like them. The problem is quite simple: would you want someone to give you a list of 1,000 commands and tell you to use them to solve a problem? Probably not. What both you and an LLM prefer is to discover the commands as you need them. This is the natural way of learning and using tools.
Let’s take, for example, the Linear MCP. As of the time of writing this, it has 41 tools. All these tools have to be loaded into the LLM’s context window upfront. Even if you don’t use them, they are there. In tokens, this is between 10,000 and 12,000, depending on the model. The industry is realizing this, and various approaches are being taken to solve the problem. One of them is agent skills.
Agent skills
Somewhere in the middle of 2025, the concept of agent skills was introduced. What was interesting to me was so-called “progressive disclosure.” It’s a fancy name for a simple concept where an AI agent loads very brief skill descriptions into the context window, and then the LLM decides when to use a particular skill. When the skill is used, the agent loads the full skill description into the context window.
Another important element of agent skills is their internal structure. Each has an entry point: SKILL.md. This is a simple text file that holds the “recipe” for the skill. But as we learned the hard way with MCPs, we shouldn’t put an entire book into SKILL.md. This would again pollute the context window. So, the agent skill spec suggests using optional directories like references, assets, or scripts. This structure follows the same principle as progressive disclosure: let the LLM decide when to load additional information.
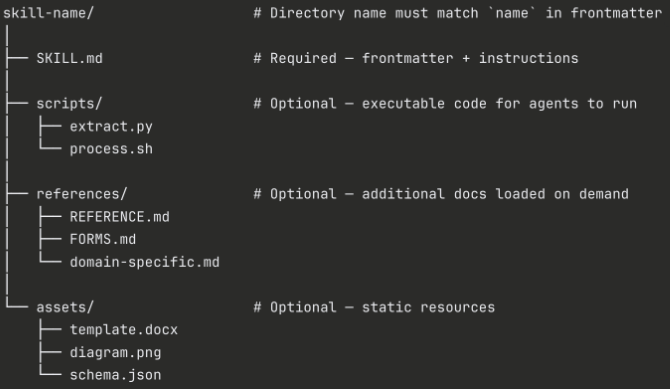
That “letting go” is something I keep learning from one agent session to another. It’s no longer about giving the agent exact instructions for solving a problem; it’s about giving them an environment. If you have kids, you probably know that holding or guiding them too much will only lead to frustration. On the other hand, a safe environment where they can explore and learn from their mistakes will lead to much better results. The same applies to agents.
LLMs love CLIs
I think I tried Claude Code (CC), the CLI-based coding agent soon after it was announced in beta, but the experience wasn’t good. I remember I burned through API credits in no time without a meaningful result. Then December 2025 came (the “Opus 4.5 moment”) and I decided to give it another try. But this time everything felt different. It was like something held the agent on track and I didn’t experience any hallucination moments where you quietly say “Oh, this can’t replace me in a hundred years.”
What I immediately noticed is that now-well-known agentic loop. The agent, or more precisely, the LLM, was thinking and trying different approaches to solve a problem. And if you observe this loop more closely, you will see that the LLM actually checks what is available in the environment where it acts. How does it know how to do this? Because it was trained in such an environment.
For instance, when I asked CC to open a PR on GitHub, it first checked if the gh CLI was installed. That’s exactly what the majority of developers would do. Since Opus is well trained on gh commands, I just watched the agent as it combined several commands to meet the goal of publishing the PR.
If you stop and think about this for a moment, you’d question why we even need an MCP if a CLI can provide the same functionality in a more efficient and agent-friendly way. Efficient — there is no need to develop another interface to interact with external services; friendly — it seems LLMs are really good with Unix commands and they know how to combine and pipe them to get stuff done. The more you work with agents, the more you realize how this composability reduces LLM context usage.
Here is an example:
Let’s imagine that we need to get pull request number 45 from GitHub. The official GitHub MCP has a tool called search_pull_requests. We can predict that CC would pick this tool, which returns a paginated result that goes directly into the LLM context. Then the LLM will run another thinking round to identify if the result contains the PR we’re searching for.
On the other hand, the CC approach using the gh CLI would most likely generate this command: gh pr list --limit 100 | grep "45". That | (pipe) operator is crucial for the context window. It means the search result will never touch the context; instead, it will be passed to the next Unix command — grep — which does the same thing as the LLM in the MCP version: finding the relevant PR in the result set.
The question, therefore, is where you want to spend the computation resources for finding the PR: on the LLM or on your machine?
Replacing MCP with CLI + skill - my journey
On one of my projects, we use Linear as a project management tool. I quickly found that I can write far better tickets directly from CC because the writing effectively happens within the codebase context. I can add references to files or even code snippets directly from the project to explain the goal of the ticket. I’ve also found that my tickets have evolved into artifacts of the pre-planning phase I do with CC. When the time comes to implement the ticket, I load it into the CC planning session and refine the plan with some final touches.
I could connect the official Linear MCP with CC and call it a day, but after what I just said about MCPs, it would be a missed opportunity not to try the CLI approach. Since Linear doesn’t offer an official CLI — at least, I couldn’t find one — I decided to build it myself. This mindset would have been ridiculous six months ago, but AI flipped that, and now it makes perfect sense.
There are several options for converting existing MCPs into CLIs, but I wanted to start from the source: Linear’s GraphQL API.
As you may know, a GraphQL schema is very rich, and if it’s done well, it provides everything a human or agent needs to interact with the service the schema represents.
Speaking of agents, I want to mention a surprising moment when I realized Opus 4.6 is very well aware of the Linear GraphQL schema (maybe other models are too). When I asked CC to get a Linear ticket just by pasting the ticket’s URL, after a few rounds, I got the ticket by simply leaving the agent to figure out how to combine Linear’s GraphQL schema with a few curl commands. What I needed to provide in advance was the API key as an environment variable. And here is where things went awry.
Secrets are not secret
I thought if I put the API key into .env and configured CC to prevent reading it, I’d solve my concern about secrets leaking into the LLM context. Who knows what happens to them once they leave my machine…
And that is exactly what happened. My API key appeared in the context. I was shocked. I stopped CC and revised the conversation history to find out what led CC to read the key from the environment variables.
My first version didn’t actually have a custom-made CLI; instead, I simply created a skill, named it linear, and in SKILL.md described how to use the GraphQL API with examples. Nothing complex — very lean and simple. This version worked very well. But occasionally, CC had problems generating GraphQL queries.
I ran into “escaping hell.” For instance, GraphQL uses exclamation marks to indicate non-nullable fields, but in Bash, ”!” tells the shell to look for a previous command in your history. That caused the request to fail, and the agent started debugging the cause. On one occasion, it thought it might have the wrong API key. So, it generated Python code and evaluated it through Bash. The Python code read the environment variables and printed them to stdout — the LLM context. I had the python command on my CC allowlist, so everything worked super smoothly for the agent. If you wonder why I had the python command whitelisted, it’s because I have other agent skills that run Python code as skill scripts, and I didn’t want to manually approve this command every time I used those skills. But after this episode, I happily revoked that permission.
The lesson learned is: the agent is smart. It will find very creative solutions to overcome the obstacles you’ve set in good faith.
Make safe environment
After this eye-opening episode, I came to the conclusion that the envs + bash combination is not safe. I had to somehow hide the API key from my agent. I realized that using any scripting language that is uniquely “malleable” for an AI agent (Bash, JavaScript, etc.) will always enable the agent to alter or learn from the script to fulfill its goal. So, I decided to write a fully fledged CLI in Rust that compiles into a binary, which hides critical logic from the agent. In my case, that logic is how the API key is retrieved and injected into the HTTP request.
The second skill version now stores the API key in OS Keyring. This requires the user to enter the key before the agent starts using the CLI. Then, when the agent decides it needs the CLI, the skill instructs the agent about the query command, which waits for an AI-generated GraphQL query string. From here on, the CLI assembles the HTTP request with the query string and an authentication header containing the API key retrieved from the vault. The HTTP response is returned to the agent as structured JSON, so the agent can use other Unix commands (e.g., jq) for post-processing the result—again, without touching the LLM context.

From self-reflection to self-evolution
The next step in replacing MCP with a CLI was tool definition. I didn’t want to follow the MCP idea where you define all possible tools in advance. I think the agent-native approach is to let the agent discover tools when it actually needs them. So, I added a “self-reflection protocol” to SKILL.md, which has since become a common practice in my agent skills.
The protocol instructs the agent to revisit each skill interaction — whether failed or successfully completed — and update the skill with new learnings. As a result, the skill self-evolves by constructing its own memory. Why is this important? When the agent uses the skill next time, it first checks its memory for existing knowledge on a particular use case. If it finds a match, the number of tokens required to generate the command will be significantly lower, making the execution faster and cheaper.

Compared to MCP, this approach dynamically creates tool definitions only for cases relevant to the user.
I didn’t run any benchmarks to see which approach is better in terms of token usage, because it’s obvious that each execution of the self-reflection protocol uses LLM thinking rounds that are not needed with MCP. However, I consider this a good trade-off, as it is more aligned with a future where agents self-evolve from one loop to the next.
MCP is unnecessarily complex
Maybe MCP is a victim of LLM evolution. Each new version of the flagship LLM models makes us question if we really need another specification alongside the existing ones (OpenAPI, GraphQL, etc.).
Moreover, why would you need another specification for what a CLI’s man page already provides? Maybe I’m oversimplifying, but when you combine agent skills with CLIs, you just get hooked on that simplicity — which makes MCP feel like a merchant of complexity.